2. Projet OpenStack
- 1. Présentation
- 2. Historique
- 3. Versions
- 4. Documentation
- 5. Architecture conceptuelle
- 6. Architecture logique
- 7. Hyperviseurs et systèmes de stockage supportés
- 8. Composants OpenStack
- 8.1. Calcul : Nova
- 8.2. Stockage objet : Swift
- 8.3. Stockage "block" : Cinder
- 8.4. Le réseau : Neutron
- 8.5. Tableau de bord : Horizon
- 8.6. Service d'identité : Keystone
- 8.7. Service d'image : Glance
- 8.8. Télémétrie : Ceilometer
- 8.9. Orchestration : Heat
- 8.10. Service de base de données : Trove
- 8.11. Traitement des données : Sahara
- 8.12. Autres services
- 9. Architecture matérielle
- 10. Architecture réseau
- 11. Ecosystème OpenStack
1. Présentation
OpenStack (parfois abrégé en O~S) est une plate-forme logicielle libre et open-source pour le cloud computing, principalement déployée sous forme d'Infrastructure-as-a-Service (IaaS), où des serveurs virtuels et autres ressources sont mis à disposition des clients. La plate-forme logicielle se compose de composants reliés les uns aux autres qui contrôlent divers ensembles matériels multi-fournisseurs de ressources de traitement, de stockage et de réseau dans un data center. Les utilisateurs le gèrent soit par le biais d'un tableau de bord Web, d'outils en ligne de commande ou de services Web RESTful.
Le modèle de déploiement est principalement dans les nuage privé mais aussi dans des offres de nuage public.
Le projet est porté par la Fondation OpenStack, une organisation non-commerciale qui a pour but de promouvoir le projet OpenStack ainsi que de protéger et d'aider les développeurs et toute la communauté OpenStack.
De nombreuses entreprises ont rejoint la Fondation OpenStack. Parmi celles-ci on retrouve : Canonical, Red Hat, SUSE, eNovance, AT&T, Cisco, Dell, HP, IBM, Yahoo!, Oracle, Orange, Cloudwatt, EMC, VMware, Intel, NetApp.
OpenStack un logiciel libre distribué selon les termes de la licence Apache.
Source : https://fr.wikipedia.org/wiki/OpenStack
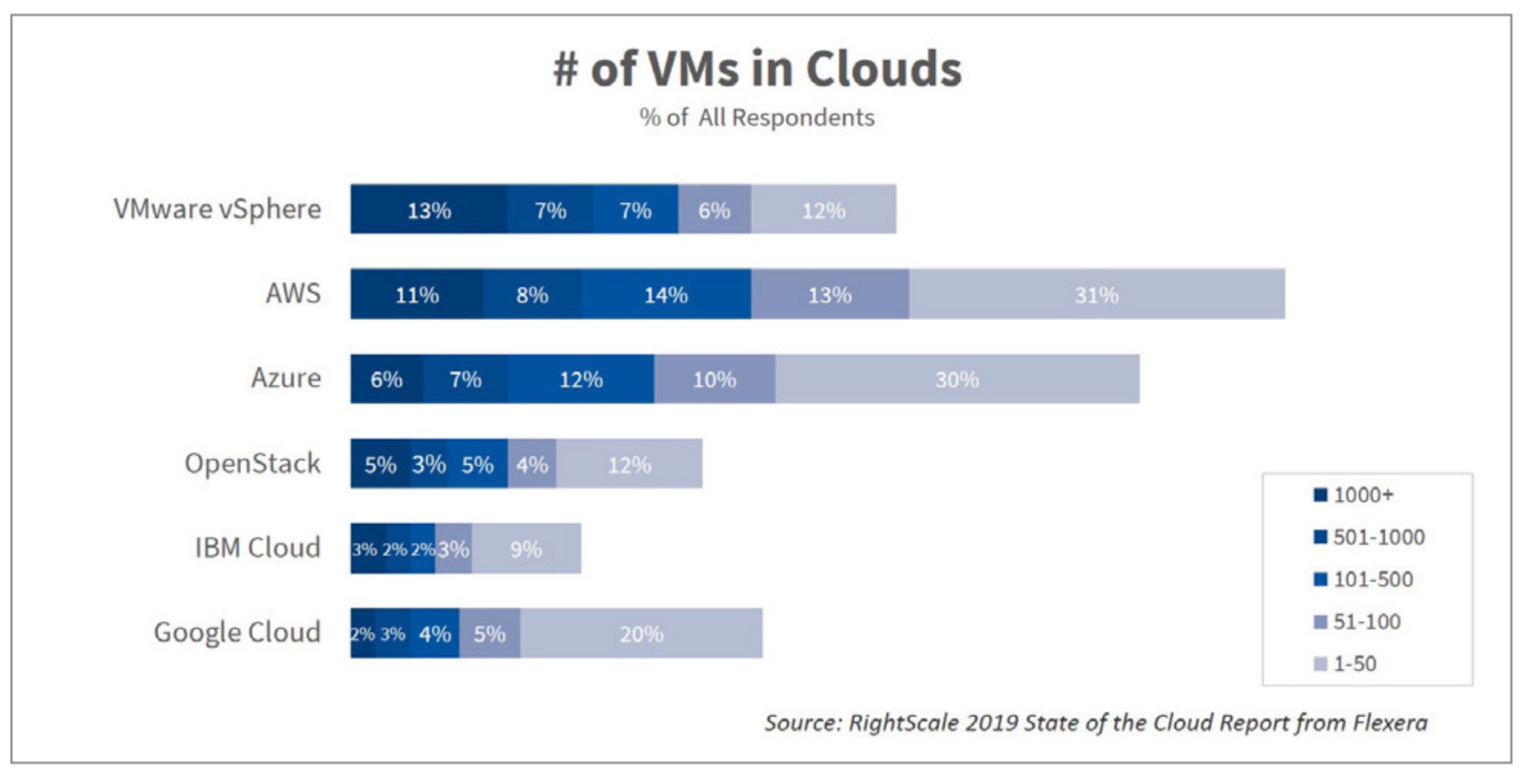
Source : https://info.flexerasoftware.com/SLO-WP-State-of-the-Cloud-2019
2. Historique
En juillet 2010, Rackspace Hosting et la NASA ont lancé conjointement un nouveau projet open source dans le domaine du cloud computing sous le nom d'OpenStack.
L'objectif du projet OpenStack est de permettre à toute organisation de créer et d'offrir des services de cloud computing en utilisant du matériel standard.
La première version livrée par la communauté, dont le surnom est Austin, fut disponible seulement quatre mois après. Il est prévu de livrer régulièrement des mises à jour logicielles à quelques mois d'intervalle.
De nombreux membres rejoignent le projet. En 2014, la communauté OpenStack compte 5600 membres et 850 organisations.
Source : https://fr.wikipedia.org/wiki/OpenStack
3. Versions
Le cycle de dévelopement d'OpenStack est de 6 mois avec la parution d'une nouvelle version qui peut être améliorée par des points de révision stables. Le nom de la version correspond au nom de la ville qui accueille les rencontres officielles OpenStack.
| Series | Status | Initial Release Date | Next Phase | EOL Date |
|---|---|---|---|---|
| Stein | Development | 2019-04-10 estimated (schedule) | Maintained estimated 2019-04-10 | |
| Rocky | Maintained | 2018-08-30 | Extended Maintenance estimated 2020-02-24 | |
| Queens | Maintained | 2018-02-28 | Extended Maintenance estimated 2019-08-25 | |
| Pike | Maintained | 2017-08-30 | Extended Maintenance estimated 2019-03-03 | |
| Ocata | Extended Maintenance | 2017-02-22 | Unmaintained estimated TBD | |
| Newton | End Of Life | 2016-10-06 | 2017-10-25 | |
| Mitaka | End Of Life | 2016-04-07 | 2017-04-10 | |
| Liberty | End Of Life | 2015-10-15 | 2016-11-17 | |
| Kilo | End Of Life | 2015-04-30 | 2016-05-02 | |
| Juno | End Of Life | 2014-10-16 | 2015-12-07 | |
| Icehouse | End Of Life | 2014-04-17 | 2015-07-02 | |
| Havana | End Of Life | 2013-10-17 | 2014-09-30 | |
| Grizzly | End Of Life | 2013-04-04 | 2014-03-29 | |
| Folsom | End Of Life | 2012-09-27 | 2013-11-19 | |
| Essex | End Of Life | 2012-04-05 | 2013-05-06 | |
| Diablo | End Of Life | 2011-09-22 | 2013-05-06 | |
| Cactus | End Of Life | 2011-04-15 | ||
| Bexar | End Of Life | 2011-02-03 | ||
| Austin | End Of Life | 2010-10-21 |
Source : http://releases.openstack.org/
4. Documentation
5. Architecture conceptuelle
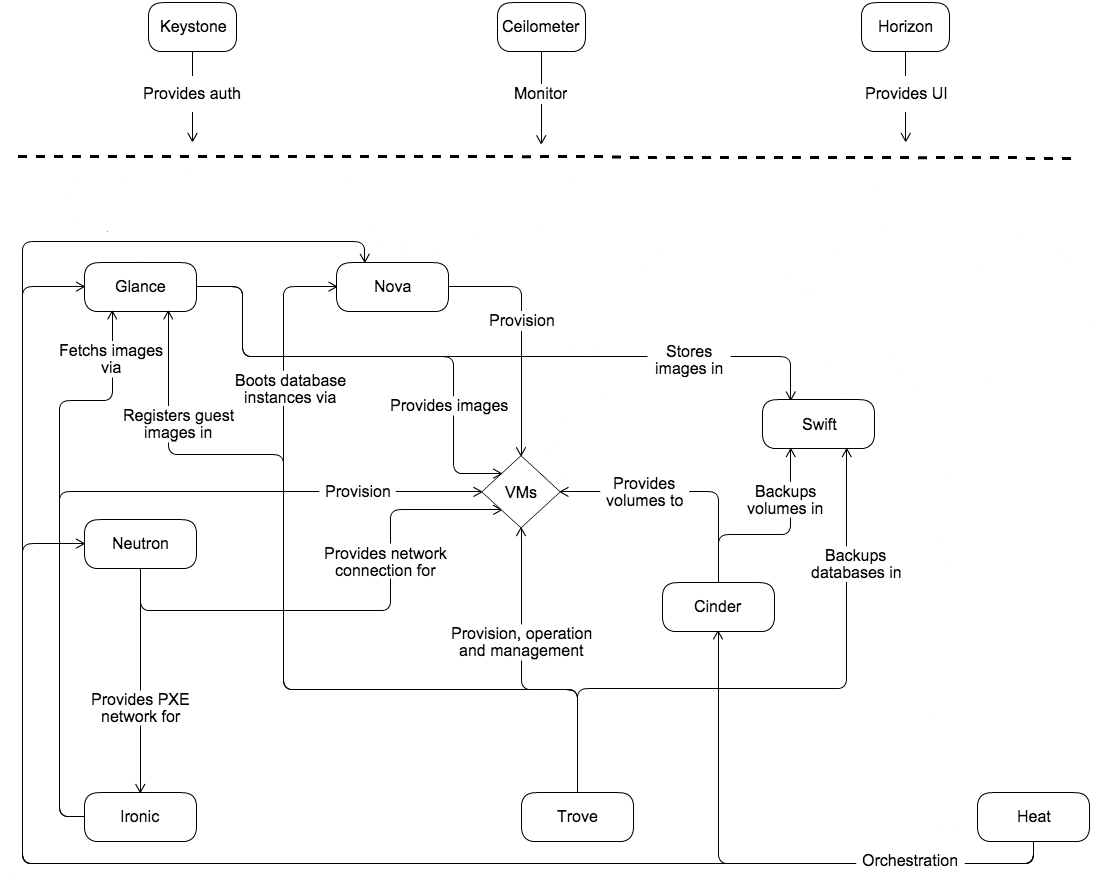
Image : https://docs.openstack.org/install-guide/get-started-conceptual-architecture.html
OpenStack possède une architecture modulaire qui comprend de nombreux composants.
6. Architecture logique
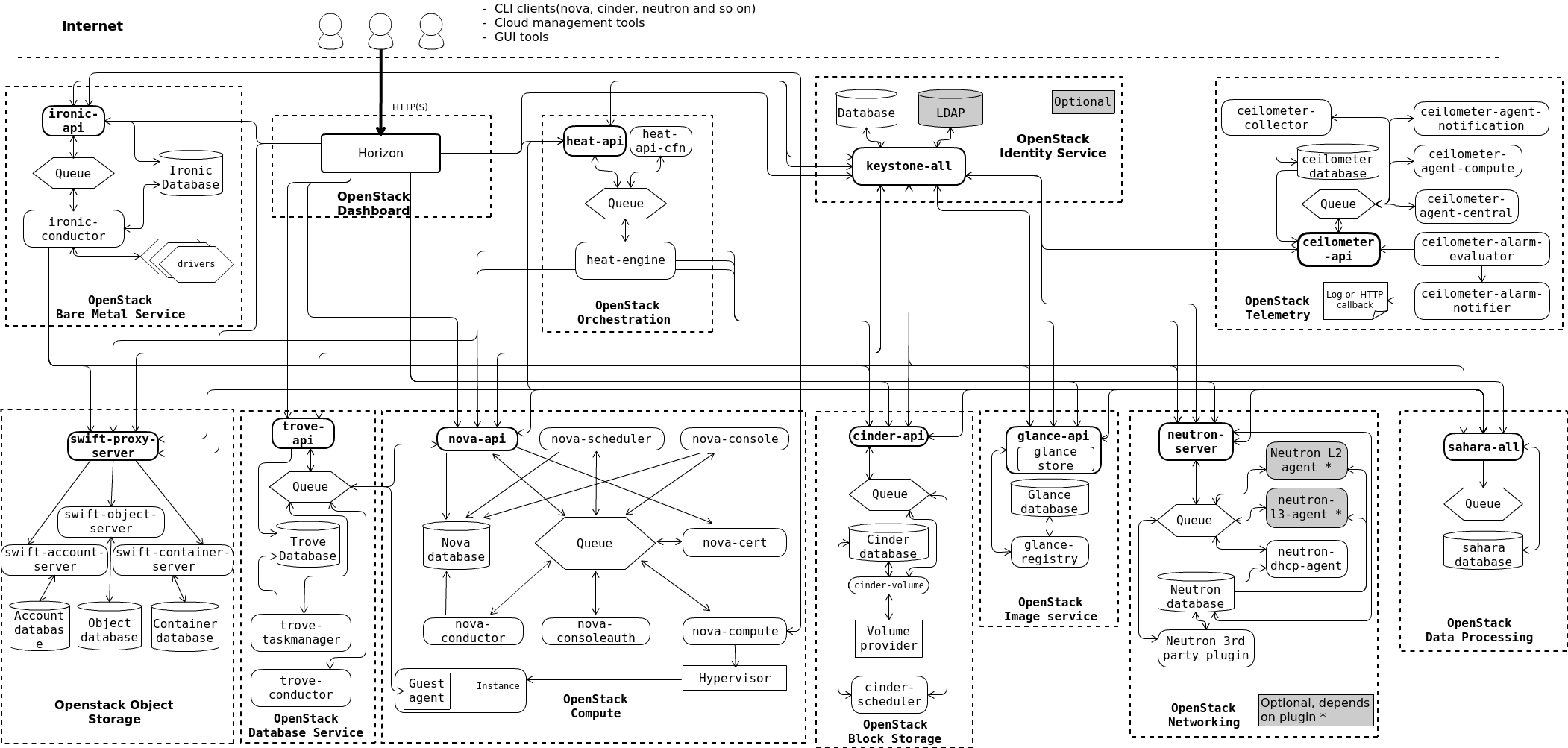
Pour concevoir, déployer et configurer OpenStack, les administrateurs doivent comprendre l'architecture logique.
Comme le montre l'architecture conceptuelle, OpenStack se compose de plusieurs parties indépendantes, appelées les services OpenStack. Tous les services s'authentifient par le biais d'un service d'identité commun. Les services individuels interagissent les uns avec les autres par le biais d'API publiques, sauf lorsque des commandes d'administrateur privilégiées sont nécessaires.
En interne, les services OpenStack sont composés de plusieurs processus. Tous les services ont au moins un processus API, qui écoute les requêtes API, les pré-traite et les transmet à d'autres parties du service. À l'exception du service Identité, le travail proprement dit est effectué par des processus distincts.
Pour la communication entre les processus d'un service, un broker de messages AMQP est utilisé. L'état du service est stocké dans une base de données. Lors du déploiement et de la configuration de votre nuage OpenStack, vous pouvez choisir parmi plusieurs solutions de courtier de messages et de base de données, telles que RabbitMQ, MySQL, MariaDB, et SQLite.
Les utilisateurs peuvent accéder à OpenStack via l'interface utilisateur Web implémentée par le tableau de bord Horizon, via les clients en ligne de commande et en émettant des requêtes API via des outils tels que les plug-ins de navigateur comme Postman ou "curl". Pour les applications, plusieurs SDK sont disponibles. En fin de compte, toutes ces méthodes d'accès émettent des appels REST API vers les différents services OpenStack.
Source : Logical architecture
7. Hyperviseurs et systèmes de stockage supportés
7.1. Hyperviseurs
La page Hypervisors donne les renseignements conernant les hyperviseurs supportés par OpenStack :
- KVM
- QEMU
- XenServer (et autres variantes Xen XAPI)
- Xen via libvirt
- LXC (Linux containers)
- VMware vSphere
- Hyper-V virtualization platform
- Virtuozzo
7.2. Stockage
OpenStack supporte les technologies de stockage :
- iSCSI
- Fiber Channel (FC)
- NFS
- Ceph
8. Composants OpenStack
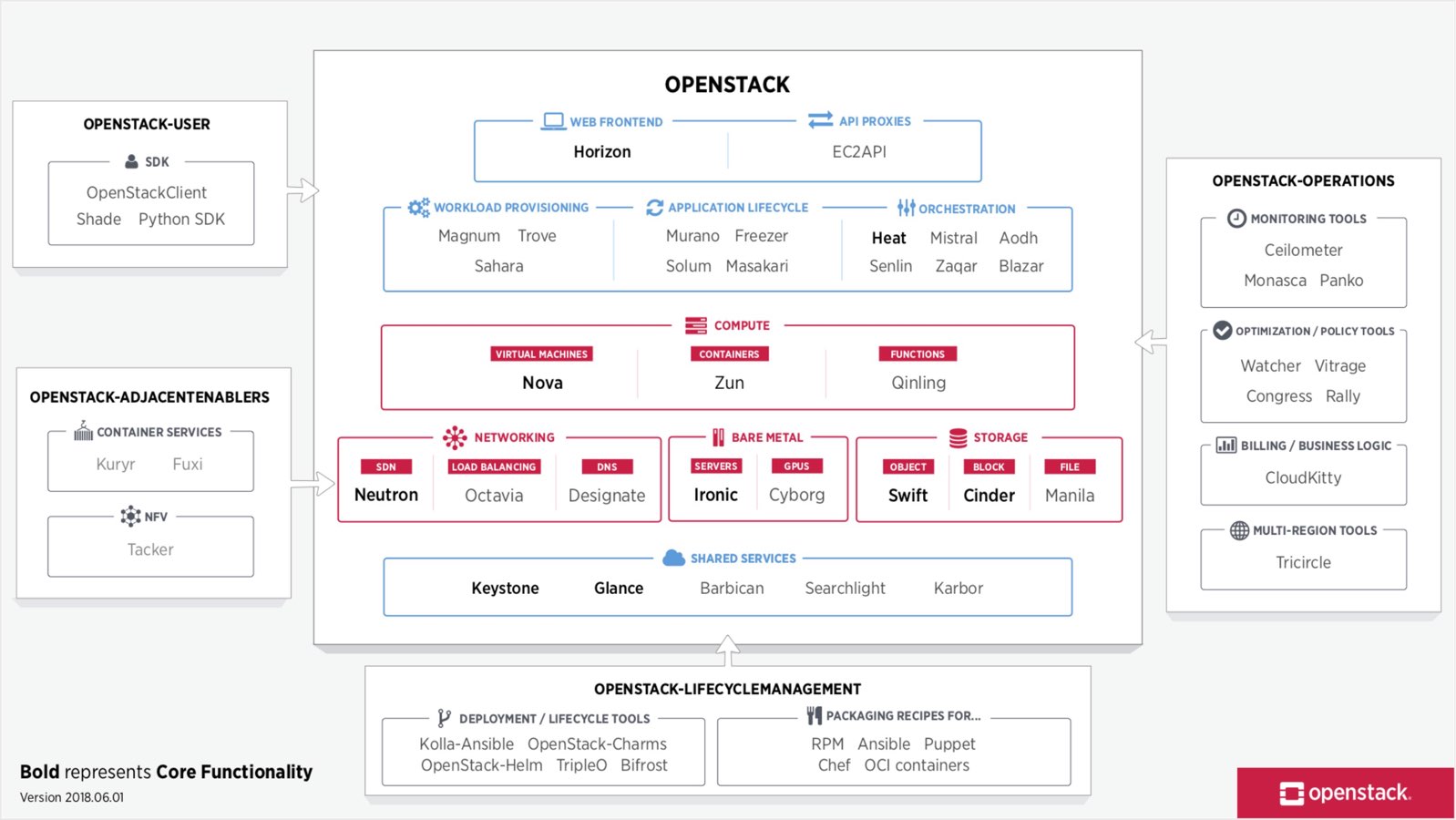
8.1. Calcul : Nova

Nova est une des briques principales d'OpenStack. Son but est de gérer les ressources de Calcul des infrastructures. Pour cela, nova contrôle les hyperviseurs par l'intermédiaire de la libvirt ou directement par les API de certains hyperviseurs. Aujourd'hui l'hyperviseur le mieux supporté reste KVM, mais nova fonctionne aussi avec Xen, ESXi, et Hyper-V voire avec des gestionnaires de conteneur comme Docker.
L'architecture de la brique de Nova est conçue pour évoluer horizontalement en rajoutant du matériel.
8.2. Stockage objet : Swift

Le stockage objet d'OpenStack s'appelle Swift. C'est un système de stockage de données redondant et évolutif. Les fichiers sont écrits sur de multiples disques durs répartis sur plusieurs serveurs dans un Datacenter. Il s'assure de la réplication et de l'intégrité des données au sein du cluster. Le Cluster Swift évolue horizontalement en rajoutant simplement de nouveaux serveurs. Si un serveur ou un disque dur tombe en panne, Swift réplique son contenu depuis des noeuds actifs du cluster dans des emplacements nouveaux. Puisque toute la logique de Swift est applicative, elle permet l'utilisation de matériel peu couteux et non spécialisé.
En aout 2009, c'est Rackspace qui a commencé le développement de Swift, en remplacement de leur ancien produit nommé Cloud Files. Aujourd'hui c'est la société SwiftStack qui mène le développement de Swift avec la communauté.
8.3. Stockage "block" : Cinder

Le service de stockage en mode bloc d'OpenStack s'appelle Cinder. Il fournit des périphériques persistants de type bloc aux instances de calcul OpenStack. Il gère les opérations de création, d'attachement et de détachement de ces périphériques sur les serveurs. En plus du stockage local sur le serveur, Cinder peut utiliser de multiple plateforme de stockage tel que Ceph, EMC (ScaleIO, VMAX et VNX), GlusterFS, Hitachi Data Systems, IBM Storage (Storwize family, SAN Volume Controller, XIV Storage System, et GPFS), NetApp, HP (StoreVirtual et 3PAR) et bien d'autres.
Le stockage en mode bloc est utilisé pour des scénarios performants comme celui du stockage de base de données, mais aussi pour fournir au serveur un accès bas niveau au périphérique de stockage. Cinder gère aussi la création d'instantanés (snapshot), très utile pour sauvegarder des données contenues dans les périphériques de type bloc. Les instantanés peuvent être restaurées ou utilisées pour créer de nouveaux volumes.
8.4. Le réseau : Neutron
Le service Neutron d'OpenStack permet de gérer et manipuler les réseaux et l'adressage IP au sein d'OpenStack. Avec Neutron, les utilisateurs peuvent créer leurs propres réseaux, contrôler le trafic à travers des groupes de sécurité (security groups) et connecter leurs instances à un ou plusieurs réseaux. Neutron gère aussi l'adressage IP des instances en leur assignant des adresses IP statiques ou par l'intermédiaire du service DHCP. Il fournit aussi un service d'adresse IP flottante que l'on peut assigner aux instances afin d'assurer une connectivité depuis Internet. Ces adresses IP flottantes peuvent être réassignées à d'autres instances en cas de maintenance ou de défaillance de l'instance originelle.
Neutron fournit différents types de déploiement réseau en fonction de l'infrastructure cible. Les types de réseaux les plus déployés sont les réseaux plats (flat network), les réseaux à VLAN, VXLAN ou à tunnel GRE. Neutron gère ses déploiements grâce à des modules complémentaires qui lui permettent de communiquer avec des équipement ou logiciel de gestions réseau. Les plug-ins les plus utilisés sont OpenVswitch, ML2, LinuxBridge, mais aussi Cisco Nexus, Juniper OpenContrail et d'autres.
Dans son architecture, Neutron a été construit en suivant la philosophie des réseaux de nouvelle génération dite SDN. Bien qu'il ne le gère pas lui même, certains plug-ins tirent parti des fonctionnalités SDN des équipements qu'ils contrôlent. Lors de son utilisation avec OpenVswitch par exemple, Neutron utilise une combinaison de règles Iptables et OpenFlow pour gérer le trafic vers les instances.
8.5. Tableau de bord : Horizon

OpenStack fournit un tableau de bord qui s'appelle Horizon. Il s'agit d'une application web qui permet aux utilisateurs et aux administrateurs de gérer leurs Clouds à travers d'une interface graphique. Comme toutes les briques d'OpenStack cette application est libre et il n'est donc pas rare de voir des versions modifiées par les fournisseurs de Cloud ou par d'autres sociétés commerciales ne serait-ce que pour y faire apparaître leur nom et logo, mais aussi pour y intégrer leurs systèmes de métrologie ou de facturation par exemple.
Cette application est écrite en python et notamment grâce aux frameworks de développement web : Django et elle tire parti des API REST fournit par les autres composants d'OpenStack comme Nova, Cinder ou Neutron.
8.6. Service d'identité : Keystone

Le service d'identité d'OpenStack s'appelle Keystone. Il fournit un annuaire central contenant la liste des services et la liste des utilisateurs d'OpenStack ainsi que leurs rôles et autorisations. Au sein d'OpenStack tous les services et tous les utilisateurs utilisent Keystone afin de s'authentifier les uns avec les autres. Keystone peut s'interfacer avec d'autre service d'annuaire comme LDAP. Il supporte plusieurs formats d'authentification comme les mots de passe et autres.
8.7. Service d'image : Glance

Le service d'image d'OpenStack s'appelle Glance. Il permet la découverte, l'envoi et la distribution d'image disque vers les instances. Les images stockées font office de modèle de disque. Le service glance permet aussi de stocker des sauvegardes de ces disques. Glance peut stocker ces images disques de plusieurs façons : dans un dossier sur serveur, mais aussi à travers le service de stockage objet d'OpenStack ou dans des stockages décentralisés comme Ceph. Glance ne stocke pas seulement des images, mais aussi des informations sur celles-ci, les métadonnées. Ces métadonnées sont par exemple le format du disque (comme QCOW2 ou RAW) ou les conteneurs de celles-ci (OVF par exemple).
8.8. Télémétrie : Ceilometer

Le service de télémétrie d'OpenStack s'appelle Ceilometer. Il permet de collecter différentes métriques sur l'utilisation du Cloud. Par exemple il permet de récolter le nombre d'instances lancées dans un projet et depuis combien de temps. Ces métriques peuvent être utilisées pour fournir des informations nécessaires à un système de facturation par exemple. Ces métriques sont aussi utilisées dans les applications ou par d'autres composants d'OpenStack pour définir des actions en fonction de certains seuils comme avec le composant d'orchestration.
8.9. Orchestration : Heat

Heat est le composant d'orchestration d'OpenStack. Il permet de décrire une infrastructure sous forme de modèles. Dans Heat, ces modèles sont appelés des "stack". Heat consomme ensuite ces modèles pour aller déployer l'infrastructure décrite sur OpenStack. Il peut aussi utiliser les métriques fournies par ceilometer pour décider de créer des instances supplémentaires en fonction de la charge d'une application par exemple.
8.10. Service de base de données : Trove

Trove est le service qui permet d'installer et de gérer facilement des instances de base de données relationnelle et NoSQL au sein d'OpenStack. À ce jour les services de base de données supportés sont les suivants : MySQL, Redis, Mongodb, Cassandra, Couchbase et Percona.
8.11. Traitement des données : Sahara

Sahara à pour but de fournir aux utilisateurs les moyens simples de provisionner des cluster de Hadoop en spécifiant plusieurs paramètres comme la version, la topologie du cluster ou d'autres. Après avoir rempli ces paramètres, Sahara déploie le cluster en quelques minutes. Sahara fournit aussi les moyens d'évolution du cluster en rajoutant des noeuds à la demande.
8.12. Autres services
| Composants de base | Service | Logo |
|---|---|---|
| Service d'identité | Keystone | |
| Service d'images | Glance | |
| Service d'orchestration | Heat | |
| Service de métrologie | Ceilometer | |
| Service de base de données | Trove | |
| Service de Big Data | Sahara | |
| Service de provisionnement bare-metal | Ironic |  |
| Service de systèmes de fichiers partagés | Manila |  |
| Service de construction de conteneur | Magnum |  |
| Service de conteneur | Zun |  |
| Service de Messagerie | Zaqar |  |
| Service de gestion DNS | Designate |  |
| Service Load Balancer | Octavia |  |
| Service de gestion de clés | Barbican |  |
| Service de catalogue d'applications | Murano |  |
| Proxy de l'API EC2 | EC2API |  |
| Backup, Restore, and Disaster Recovery | Freezer |  |
et bien d'autres : OpenStack Components : Services
9. Architecture matérielle
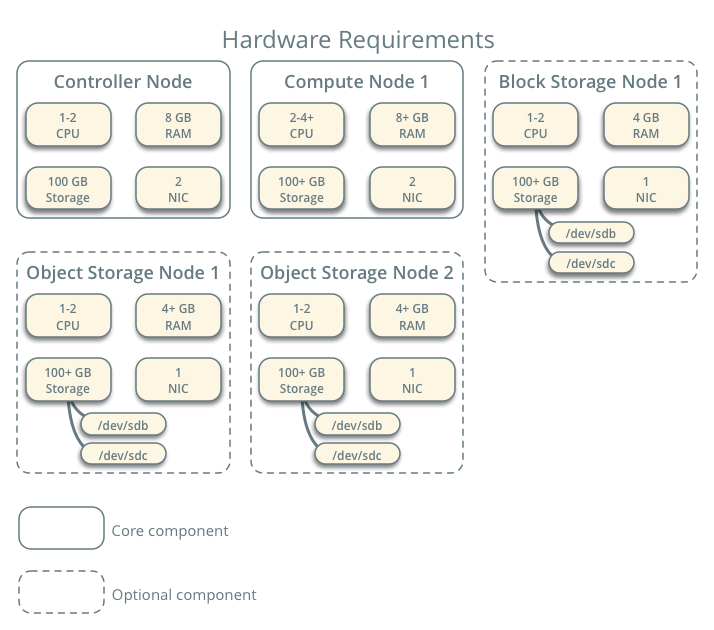
Cet exemple d’architecture diffère d’une architecture minimale de production par ce qui suit :
- Les agents réseau tournent sur le nœud contrôleur plutôt que sur un ou plusieurs nœuds réseau dédiés.
- Le trafic "overlay" (tunnel) des réseaux privés traverse le réseau de management au lieu d’un réseau dédié.
9.1. Contrôleur
Le noeud contrôleur fait fonctionner le service Identity, le service Image, les parties de gestion de Compute, la partie gestion du service Réseau, divers agents Réseau et le tableau de bord (Dashboard). Il supporte aussi des services comme des bases de données SQL, NTP ou Messages Queuing (MQ)
En option, le noeud contrôleur peut faire tourner des parties de services de Stockage par Blocs, de Stockage Objet, d’Orchestration et de Télémétrie.
Le noeud contrôleur nécessite au minimum deux interfaces réseau.
9.2. Compute / Calcul
Le noeud compute exécute la partie hyperviseur de Compute qui fait fonctionner les instances. Par défaut, Compute utilise l’hyperviseur KVM. Le noeud compute héberge également un agent du service Réseau qui connecte les instances aux réseaux virtuels et fournit des services de firewall aux instances via les groupes de sécurité.
Vous pouvez déployer plus d’un noeud compute. Chaque noeud nécessite au minimum deux interfaces réseau.
9.3. Stockage par Bloc
Le noeud optionnel de Stockage par Blocs contient les disques que les services de Stockage par Blocs et de Systèmes de Fichiers Partagés provisionne pour les instances.
Pour simplifier, le trafic du service entre les nœuds compute et ce nœud utilise le réseau de management. Les environnements de production devraient implémenter un réseau de stockage séparé pour accroitre la performance et la sécurité.
Vous pouvez déployer plus d’un noeud stockage. Chaque nœud nécessite au minimum une interfaces réseau.
9.4. Stockage Objet
Le noeud optionnel de Stockage Objet contient les disques que le service de Stockage Objet utilise pour stocker les comptes, les conteneurs et les objets.
Pour simplifier, le trafic du service entre les noeuds compute et ce noeud utilise le réseau de management. Les environnements de production devraient implémenter un réseau de stockage séparé pour accroitre la performance et la sécurité.
Ce service nécessite deux noeuds. Chaque noeud doit avoir au minimum une interface réseau. Vous pouvez déployer plus de deux noeuds de stockage objet.
Autre exemple (RedHat)

10. Architecture réseau
10.1. Réseau Option 1 : Réseaux fournisseurs
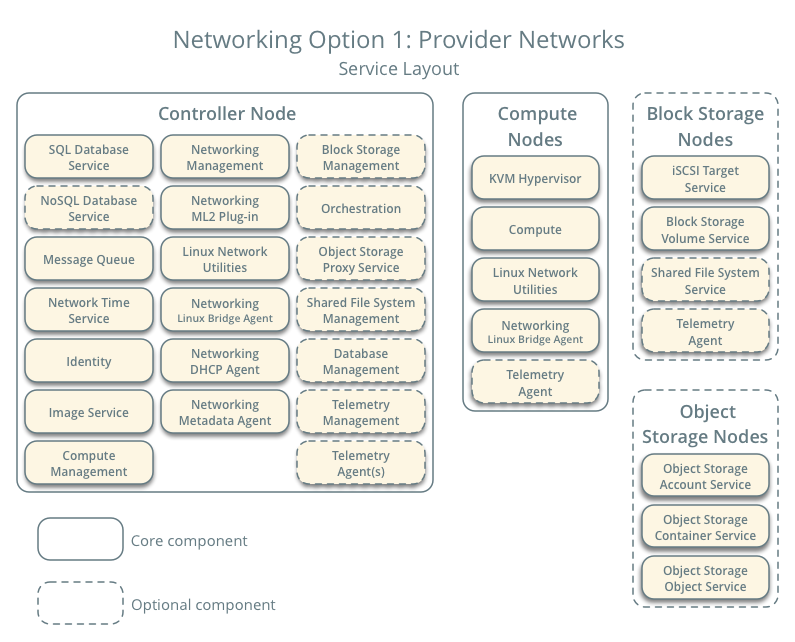
L’option de réseaux fournisseurs déploie le service Réseau d’OpenStack de la façon la plus simple possible avec essentiellement les services de couche 2 (bridging/switching) et une segmentation des réseaux en VLAN. Principalement, il fait le lien (bridge) entre les réseaux virtuels et les réseaux physiques et s’appuie sur l’infrastructure réseau physique pour les services de couche 3 (routing). De plus, un service DHCP fournit les informations d’adresse IP aux instances.
10.2. Réseau Option 2 : Réseaux libre-service
L’option de réseaux libres-services améliore l’option de réseaux fournisseurs avec des services de couche 3 (routing) qui permettent la création de réseaux libres-services utilisant des techniques de segmentation overlay comme VXLAN. Essentiellement, cela permet de router les réseaux virtuels vers les réseaux physiques via le NAT. De plus, cette option sert de base aux services avancés comme LBaaS et FWaaS.
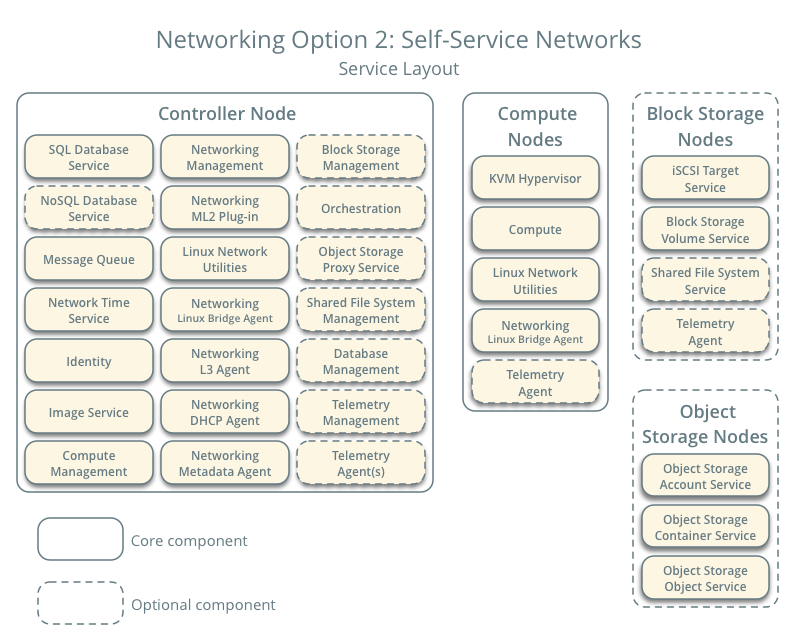
Source : https://docs.openstack.org/ocata/fr/install-guide-ubuntu/overview.html#networking